In a previous article we introduced the core concepts of triaging: the origins of the term in emergency medicine, what it means to have triaged a ticket in the world of software development, and the basic metrics around doing it well. In this follow-on article, we will look at a few of the subtleties in this very first part of a team’s workflow, the steps from ticket creation through to finishing triage.
So what are the ways these steps can vary between teams? Let’s consider a few:
Who can create tickets?
Teams can and should formulate (then publicise, and enforce) their own rules around this. At one extreme, it could be “anyone at all”, even people outside the organisation. Or you could be more restrictive: only people inside the organisation, only people in this particular department, only members of this team, only selected members of this team, or only one particular person.
There’s a trade-off here: the smaller the number of people who are allowed to create tickets, the easier it is to standardise the ticket creation process around your optimal set of requirements (eg what data fields must be filled in so a ticket is triageable), but the more you need to work to establish good comms methods for allowing outside people’s work requests to be translated into tickets by these Creators. If, on the other hand, Ticket Creation is open to many people, the team needs to carefully police the quality of created tickets, and publicise guidelines around doing so. There’s no right answer here – each team has to figure out their own arrangements by an empirical process of trial and error.
Who can triage?
Again, this is contextual, but a typical arrangement is that the Triage Team is a combination of internal team management roles, people with such titles as ‘Tech Lead’, ‘QA Lead’ and ‘Product Owner’.
What needs to be recorded?
Agile doesn’t mean chaos or never writing anything down, but there’s no point being wasteful and requiring unnecessary documentation either. With triaging it is often sufficient to take less than a minute to make just a single comment (eg in a Jira ticket) along the lines of “Ticket triaged by Rob and Jenny – bottom of the backlog”. That simple audit trail can save a mountain of pain later.
How do you keep on top of your triaging?
Given that we want Triage Time and Untriaged Count to be as near to zero as possible at all times, we need untriaged tickets to show prominently somewhere, as a reminder that there is triaging to do. Jira, arguably the most powerful work management system commonly used by software teams, tends to dump minimally-filled-out new tickets right at the bottom of the backlog, where they might not get looked at for a very long time. If you are in that situation, you need to have a robust team process to combat Jira’s tendency to hide these new tickets away.
When I run tech teams, I often take on myself the task of scanning the bottom of the Jira backlog several times a day for recently-created, untriaged tickets. I would then move such tickets into the ‘Triaging’ state, stick them (temporarily) high up the backlog so they get noticed by all on the team’s Agile Board, I comment/assign them so my Triage Team are additionally notified by email to make the priority call, and as appropriate use other comms methods (F2F, IM etc) to make sure they know of the incoming wounded. None of this is very onerous if done “little and often”, and it has worked very well in multiple teams.
What options are there for representing triaging on an Agile Board?
In an earlier article we looked at one simple pattern for representing the early part of a team’s workflow, where triaging itself is represented by a single step, with no buffer states on either side:
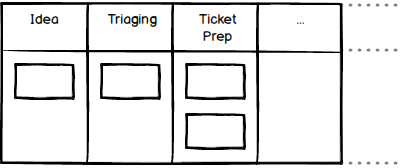
The meaning of the columns in this case would be:
Idea: a ticket has been created in the system, nothing more. It may or may not be fit for the next step in its life. If not, this could be because it contains mostly garbage, or perhaps because it hardly contains anything at all. The creator, with or without help, must rectify this before the ticket can progress.
Triaging: in the absence of any buffer states, this column contains tickets that have been assessed as ‘fit to be triaged’ but where that process has not yet started, and those currently undergoing triaging.
Ticket Prep: in the absence of any buffer states, this column now represents tickets that ‘have been triaged and no more’, and tickets where in addition ‘more detailed ticket prep has already started’.
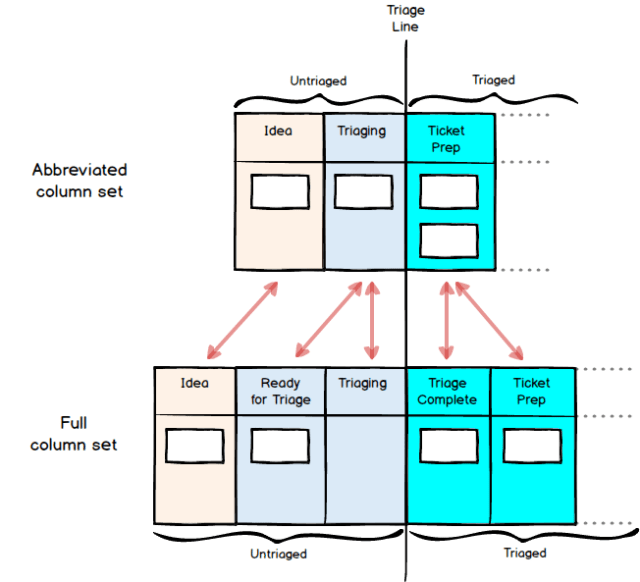
An alternative Agile Board setup, with buffer states either side of the main Triaging activity, might look like this:

This time the column semantics are as follows:
Idea: a ticket has been created in the system, nothing more. Nobody other than its creator necessarily knows what’s in it.
Ready for Triage: this “pre-state buffer” means that someone has checked the information in the ticket, and verified that it is sufficient for a triage decision. If such a check reveals that a ticket has failed to meet this standard, that ticket stays in the Idea state and is appropriately reassigned and commented.
Triaging: the triage itself is happening now.
Triage Complete: a “post-state buffer”. Triaging has finished, meaning that the ticket has been placed in an appropriate slot in the team’s priority-ordered list of work. Nothing more has yet happened.
Ticket Prep: the next major step in the ticket’s life after triaging has now begun
This extra detail on the board has a cost and a benefit. Having a large number of columns can cause issues both with physical boards (are they wide enough to fit all the columns?) and software boards (does your monitor have enough pixels to display all columns legibly?). The benefit is that you are more accurately able to represent what is really going on – see how much easier the column semantics were to explain in the second example above. Teams must figure out by trial and error what columns work best for them, but I often find that you can pare columns down around the activity of Triaging, but definitely need buffers around some downstream activities such as Dev and QA. Buffer states will be discussed in more depth in a future article.
How exactly do I collect Triage metrics?
The two metrics introduced in the previous article, Triage Time (average time to get new tickets triaged) and Untriaged Count (how many current tickets haven’t finished triage yet), are read off your Agile Board, and so of course depend on how the board is set up. In the two examples we are discussing, the detailed setup contains three columns where tickets would count as untriaged, and the simple setup just two, as illustrated below. The diagram below shows how the columns map to each other across the two variants, and the “Triage Line” indicates the point at which triaging has been completed in each case:
To conclude, if you care about smooth and efficient software delivery, there’s much important work to be done well before the first line of code is written. It’s notable that many teams focus only on modelling and tweaking the delivery part of their workflow, and sorely neglect the upstream steps, such a triaging. This neglect only stores up problems that come to light during delivery itself, when they are much more costly to fix. Hopefully between this article and the previous one you have the guidance you need to put a robust Triage Process in place in your teams; the rewards for doing so will be felt throughout the rest of your work.
