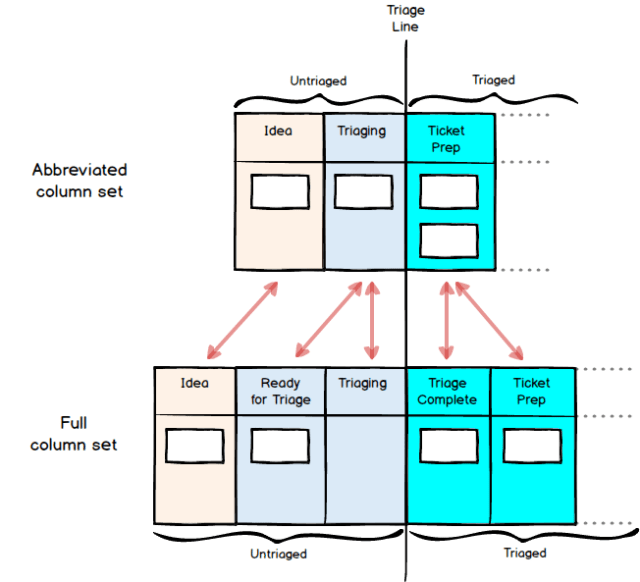
 In a previous article we outlined the steps for a hypothetical, generic software development team to get work from its starting state of ‘Idea’ to the key intermediate state, ‘Ready for Dev’ (R4D):
In a previous article we outlined the steps for a hypothetical, generic software development team to get work from its starting state of ‘Idea’ to the key intermediate state, ‘Ready for Dev’ (R4D):
| getting tickets ready |
delivering |
| Idea |
Triaging |
Ticket Prep |
Hand-shaking |
R4D |
bla… |
Done |
This article will examine what steps might follow, all the way to the nirvana that is ‘Done’, which means that code is tested and working in production, in use by real customers of the business, and hopefully generating some value for the organisation.
The next step after R4D is, uncontroversially, ‘In Dev’. Is this just ‘writing the code’? In fact it is that, and more. For this step, as for all steps in the workflow, the team needs to explicitly agree, and then adhere to, their own criteria for what it means to have successfully completed the step. Typically for ‘In Dev’ this includes meeting team rules around coding standards, writing appropriate unit and integration tests, version control usage and so on.
Whatever specifics the team decides on this, the point at which a ticket goes into the ‘In Dev’ state is a critical point in its lifecycle. As a general rule, much more work, and work that is much more difficult and costly to undo, happens during and after this stage than what went before. This matters greatly when, as is inevitable, the prospect arises that the specifications or the priority of a given piece of work should perhaps be amended.
These decisions should be made on the basis of a cost-benefit analysis, and it is precisely at ‘In Dev’ that the cost element rises considerably, raising the bar on giving the go-ahead to such changes. This means that putting a ticket into ‘In Dev’ should never be done frivolously, as it represents a step-change in the team’s commitment of effort. Promoting the right kind of discipline around this is one of the key functions of the pre-R4D states on the board.
| getting ready |
ready |
delivering |
| Idea |
bla… |
R4D |
In Dev |
? |
? |
? |
? |
? |
Done |
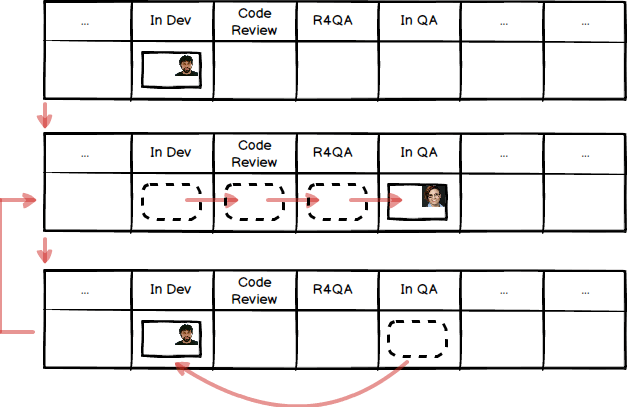
What happens after ‘In Dev’? Coding is so important and difficult to get right that it is usually worth rigorously double-checking, and we call that out in our workflow under a separate step, here named ‘Code Review’. How that reviewing happens is again for the team to decide. Sometimes just a quick look from one other person is sufficient, but at other times you might need multiple people to check multiple times before work passes muster. Tools such as Github’s Pull Request review system are often used to make this intra-dev communication easier, and a single PR can end up with dozens of comments from multiple people. It’s usually best practice to summarise the results of that conversation in a more widely-available place, where those unable or unwilling to use Github can see the outcome; the obvious place is the tool used to generate the Agile Board, such as Jira.
Some teams consider that the practice of pair-programming – where two programmers collaborate closely at the same screen/keyboard to write code together – counts as ‘Code Reviewing As You Go’, and therefore any code that results from pairing needs no further checking stage. But it’s a rare team that applies this practice to absolutely every piece of work (I’ve only known one to do so in nearly 20 years in software development), and so it’s a rare team that cannot benefit from a separate ‘Code Review’ step on their Agile Board.
| getting ready |
ready |
delivering |
| Idea |
bla… |
R4D |
In Dev |
Code Review |
? |
? |
? |
? |
Done |
When a ticket has passed Code Review, that means the Dev sub-team considers the ticket ‘code complete’; in other words, that their work is done. Sadly this is often ludicrously far from the truth, and people can be delusional about how much work still remains to be done, with multiple steps of getting code merged, tested, approved and deployed. This cartoon puts it well:
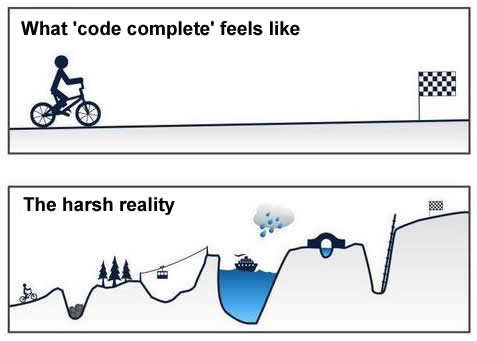
Credit
In our hypothetical team, after Code Review it is the turn of the QA (Quality Assurance) aka Testing sub-team to do their stuff. Given that the QA team is often overstretched, and is hardly ever able to pick up every ticket the very moment it passes Code Review, we need a buffer state next called ‘Ready for QA’, the inbox for the QA team.
| getting ready |
ready |
delivering |
| Idea |
bla… |
R4D |
In Dev |
Code Review |
Ready for QA |
? |
? |
? |
Done |
The QA sub-team picks from this ‘Ready for QA’ column, in priority order of course. QA work is often a mix of coding high-level acceptance tests, and manual testing. How much of each depends on what is being tested (front-end and mobile apps need more manual testing than pure server-side code with no UI), the skills of the testing team, and the technical maturity of the team overall.
For this example workflow we will include all of this under a single step, ‘In QA’, though this step can be broken out into separate sub-steps for Automated and Manual QA if required. If a team aspires to a BDD model, some or even all of the Automated Tests might have been written in parallel with, or even before, production code was written at the ‘In Dev’ stage. In my experience few teams manage anything like this BDD ideal in practice, but if a team does this or is determined to try, they would amend their workflow model accordingly, perhaps by having a step for ‘Automated Tests’ after R4D, before ‘In Dev’. But I will stick with a simpler workflow for now in this example, this single step called ‘In QA’.
| getting ready |
ready |
delivering |
| Idea |
bla… |
R4D |
In Dev |
Code Review |
Ready for QA |
In QA |
? |
? |
Done |
What does it mean to finish this step? As ever, each team must develop and follow its own rules, but a common approach is that finishing this step means: code has been validated against its specification by the QA sub-team, that relevant bugs have been raised (as separate-but-linked tickets and/or as part of the ticket being tested), that bugs above some agreed impact threshold have been recoded, retested and are now passing, and that the ticket as whole is therefore considered deployable to the Live environment by both of the technical sub-teams, QA and Dev.
At this point a quick discussion of environments is in order. In these articles I am keeping discussion of technical considerations to a minimum, as they are complex and polemical in their own right. Nevertheless it is pretty much universal that business value is only provided when code is accessible to real users in a Live (or ‘Production’) environment, and that all the pre-steps we have been discussing happen in various lower environments. Quite which environments and what names they go under varies widely, although it is (unsurprisingly) a common pattern that QA steps happen on an environment called ‘Test’, where code from multiple different developers has been merged. The very purpose of both the QA steps and the Test environment is to give us sufficient confidence to deploy the new code to Live without panicking that our users’ world will collapse as a consequence. The dire consequences of not having separate Test and Live environments is the subject of dark humour in the industry:
So, post-QA, are we ready to deploy to Live? In some teams, yes. In others, the Product function prefers a formal Sign-off stage. If everything prior to Sign-off has been performed correctly, this should be a formality, and (like any step) if it is found to generate little value then the team should consider a process simplification, removing that step both from what they do and how they model it on an Agile Board. But sometimes a Sign-off step is required, and it is not prima facie unreasonable for the person who requested the work (ideally that very individual, often a BA or Product Owner) to confirm whether they’ve got what they asked for, neatly completing a request-response loop and avoiding much potential embarrassment from the wrong thing going Live.
| getting ready |
ready |
delivering |
| Idea |
bla… |
R4D |
In Dev |
Code Review |
Ready for QA |
In QA |
Sign-off |
? |
Done |
Note that calling out a formal Sign-off step does not have to mean a team is going down a stratified, siloed, somewhat Waterfall way of working. As we have stated in previous articles, a board is necessarily a simplified model of a workflow. One of the most obvious simplifications is that it represents steps in a single, linear flow, with a particular team sub-function usually having the major responsibility for each step. But in well-functioning, well-integrated teams, the reality may be far more fluid; pairs or small groups from different sub-functions can and often should work together at multiple stages of the flow. It is a sign of good teamwork when you hear comments such as “that ticket can go straight to Sign-off from Code Review – Dev X and QA Y have been pairing on it the whole time, so it has already been tested”, or a Product person says “that one can count as signed-off already; I went through it all at QA Z’s desk yesterday when she was testing the last part”. I will never complain when, without cheating, a ticket shoots through some stages of its life on its journey to Done.
Now, after Sign-off, the ticket is indeed Ready for Live. I have known server teams with completely automated continuous deployment pipelines where this step (and several others) are unnecessary; it is an automated script on a CI server that auto-deploys any code whose tests turn a dashboard green on a lower environment, so there’s no human intervention required, insufficient time for them to do so even if they wanted, and therefore no point representing such steps on an Agile Board. But equally there are many teams where the work and process required for a Live deployment is sufficient, and sufficiently separate, to justify a ‘Ready for Live’ column on the board. One we’ve added that, we have a complete workflow from ‘Idea’ to ‘Done’, and the resulting Agile Board looks like this:
Calling something ‘Done’ means there is nothing more for this team to do. Some teams (perhaps with a sub-optimal tech pipeline) in fact do need to do further explicit checks in the Live environment itself, and in this case they may need to add further columns to represent that work, but in this hypothetical team we will take ‘deploying to Live’ as the last thing that this team needs to do.
In fact from the organisational perspective it is rarely true that no more work at all applies to what you have just deployed. Someone should be checking on the take-up amongst real users of that lovely new feature you spent two months building – if it is widely used, perhaps it should be enhanced. If it’s not used at all, perhaps it should be redesigned or removed. This is the Lean Startup Build-Measure-Learn loop, where all of these workflow steps are just the ‘Build’ part.

But the timescales over which the Measure and Learn steps happen are often large, and usually involve relatively few people from the software development team itself, and so while that monitoring and thinking could (and probably should) be modelled on some Agile Board, it is usually not put onto the development team’s board – at least until the loop has completed and new work arrives in the guise of new tickets ideas all the way over on the left of the dev team’s board, and the cycle begins again:
So now our hypothetical dev team has a complete board, the next step is to make sure we use the board in the right way. And that means we need to know how to read it properly, which is the subject of the next article.

















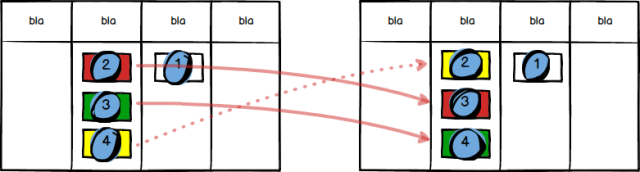
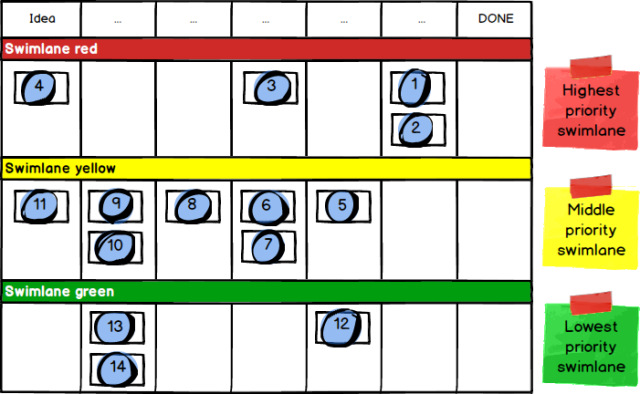
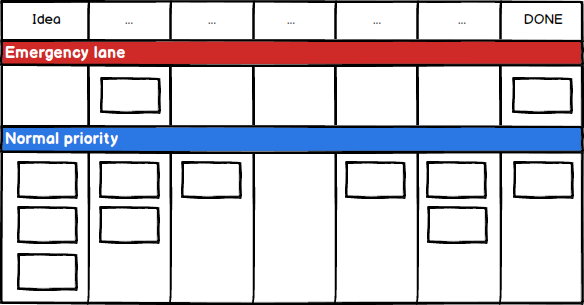
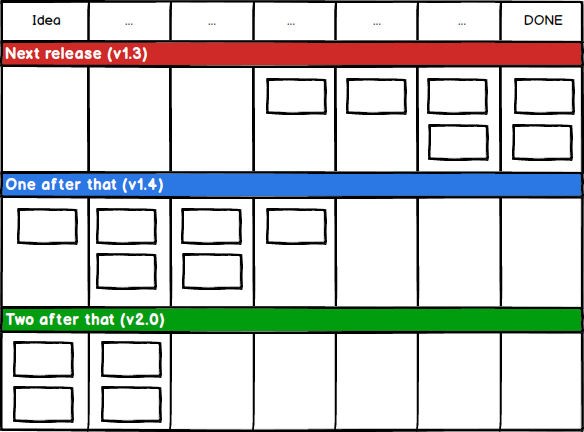
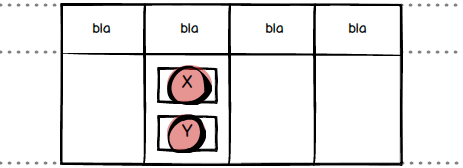

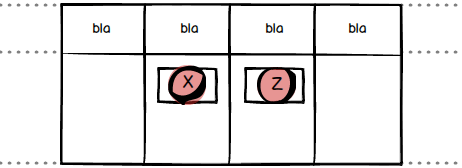
 The third and final quiz question is a combination of the two above. Again, other things being equal, in which order should someone pick up the following three tickets?
The third and final quiz question is a combination of the two above. Again, other things being equal, in which order should someone pick up the following three tickets?





You must be logged in to post a comment.