You’re a day away from a release deadline, and disaster strikes; two of your four QAs, half the team, are struck down with a nasty stomach bug. We need to sort out immediately what that means for our release; what testing work has already started and now needs to be reassigned, and what hasn’t even been started yet, and will therefore probably get dropped out of this release entirely. Does our Agile Board help with such decisions by making it instantly obvious what has started, and what hasn’t?
This is the kind of common real-world situation that can be helped by the good use of “buffer states” on your board, and that is the topic of this article.
As we know from previous articles, an Agile Board shows the workflow of a team, the series of steps its work goes through on the journey from conception to finished. Along the way the work is passed along a virtual production line, with various different combinations of people engaging in different value-adding activities, until we get the finished product.
The ideal is that the delays between (and within) each of these value-adding activities is minimal or even nil, the appropriate metaphor being a slick sprint relay race:

Unfortunately the real world is rarely anything like this. A good team might approach this ideal in dealing with an Emergency, where everything is sacrificed for speed whatever the cost in disruption elsewhere, but for normal work there will most certainly be gaps where work sits idle. In fact, when measured, most work spends a shockingly high percentage of its life sitting around unattended, waiting to be picked up. The metrics of work idleness*, ‘touch time’ and ‘flow efficiency’, will be the topic of a future article, but for now it should be clear that reducing such idleness to a minimum is one of the main objectives of a good team, and visual management of idle work is essential to that goal.
This means separating out such idle states and making them visible as columns on an Agile Board, appearing as ‘in-between’ columns or ‘buffer states’ that separate out the columns for the main value-adding activities.
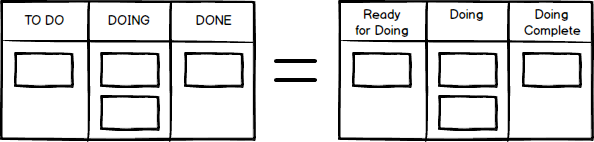
If you’ve ever worked with an Agile Board you have likely come across buffer states, even if you didn’t think of them that way. Even the simplest board of all, “To Do — Doing — Done” is really nothing more than a couple of buffer states around a single activity, and it can be rewritten to a format that makes this explicit:
Let’s apply this thinking to the example workflow sketched out across two previous articles (here and here), to see what we can learn. After such an exercise we will have a deeper understanding of this workflow, and will have a conceptual framework for further tweaking and improvement. Here it is again, a complete workflow across a dozen columns:

These columns tell us that we started with an idea, and then applied the following list of discrete activities to it:
- Triaging
- Ticket Prep
- Development
- QA
- Sign-off
- Deployment to live
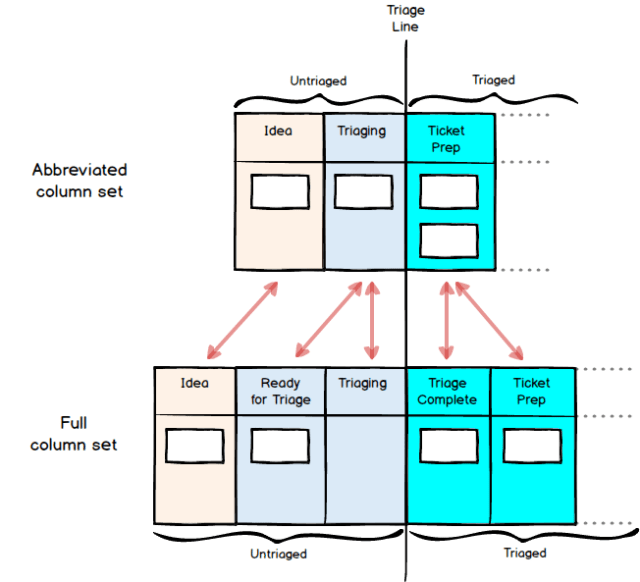
So what happens if we take this list, and just wrap each item in buffer states? Let’s do that for the first two adjacent activities, Triaging and Ticket Prep, and see what results: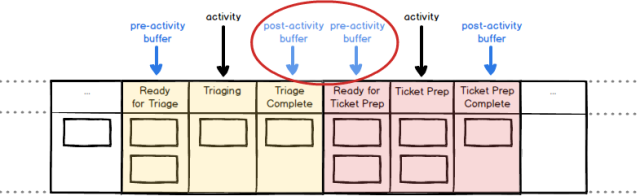
The first thing to notice here is that we end up with two buffer states next to each other, which makes no practical sense. A ticket which has completed Triage simply is ready for Ticket Prep, so the two columns Triage Complete and Ready for Ticket Prep are duplicates. One of the redundant columns must be removed; it doesn’t matter much which one goes, but it’s nonsense to have both.
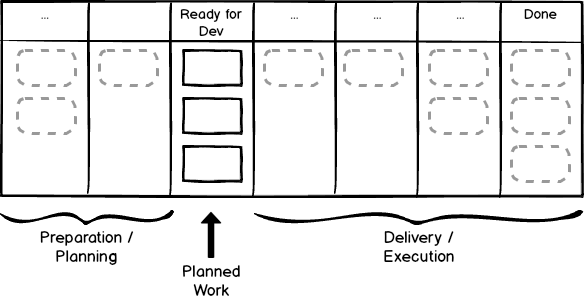
With this in mind, let’s see what happens if we apply just a pre-activity buffer, ‘Ready for X’, before each of the six main activities in the workflow. This gives us the 14 column workflow below, with the buffer states highlighted; collectively, they now show all the states where no value-adding work is being done.

Comparing this to the original workflow, two useful steps have been lost, Handshaking and Code Review. These are neither buffer states, nor a main activity state. Instead, both of these are reviewing steps – Handshaking is a review of the Ticket Prep activity (to see if it was done to the required standard), and Code Review is the same for the Dev step. Let’s insert these two states back into the workflow, renamed to be consistent with the other steps as “Ticket Prep Review” and “Dev Review”. This gives us the 16-state fully-buffered workflow below:

Now let’s compare this to the original 12-state workflow, with its (three) buffer and (two) review states highlighted:

So which of the two is better? The differences come down to column naming (which is a matter of taste), and whether every discrete activity is buffered. Is it actually better to buffer every activity?
Arguably it is. In a previous article on triaging, we saw that that buffer states make it easier to describe the precise meaning of each column, as you are no longer munging both waiting and doing into a single column. Is that sufficient to declare we should always buffer every activity on a board? Not quite; there is a countervailing pressure, that Agile Boards with too many columns can become cumbersome and hard to scan and read, whether they are physical or implemented in software.
Physical boards with 16 columns are relatively rare; you need a mighty wall to display it on, and there aren’t too many of those available in most offices. For software boards, the limitation is the legibility of a screen with many columns on it. If everyone in your office has monitors with huge resolution, or (perhaps soon!) Minority Report style VR screens, you won’t be affected by this limitation. But most of us will sadly run out of wall inches or readable pixels, and so there is some reason to limit the number of columns where possible, unless you wish to split the board in two (which can be done – I will cover this in a future article).
Let’s return to our original 12-state workflow, and see what buffer states are and are not included. It turns out that none of Triaging, Ticket Prep or Sign-off are buffered, and Deploying to Live is effectively unbuffered as well, with one column (‘Ready for Live’) representing both buffer and activity itself. Activities that are buffered are Dev and QA. What are the reasons for treating different activities in this way?
In the real teams where this very Agile Board setup worked well, the unbuffered activities of Triaging, Sign-off and Live Deploy were relatively quick, uncontroversial and unlikely to go wrong, and so were able to function with a less detailed board representation. Coding (Dev) and testing (QA) are almost always, by contrast, multi-factorial and highly complex activities, drawing on the bulk of the team’s manpower and budget, and with equivalently high need for transparency, hence the decision to buffer those columns.
Between Triaging and Ticket Prep a buffer might have been helpful, but both activities were owned by the same Product sub-function, and so tended to be run by the same small group of people. The resulting good interpersonal communications and the ease of ‘handing work over to yourself’ meant that extra detail on this part of the board was unnecessary to smooth team operations.
So it turns out that the buffering decisions on this Agile Board were well fitted to its context; there is a rationale for buffering some activities but not others. A fully buffered Agile Board may be a wonderful thing – but if you can reduce column count without compromising the flow of work, that is also fine. And the only test that matters is the empirical one of whether your setup works well in practice.
Finally, I will show a slightly different kind of board setup which you sometimes see in the literature and in the workplace. Many Agile Board software systems do not allow sub-columns (which is why my examples show simple columns that are the height of the whole board), but some software systems do, and of course on a physical board you can have any setup you like within the available space. Allowing sub-columns leads to slightly different board layouts such as the following, taken from this book:
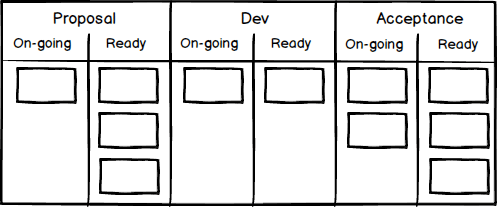
Whatever you think of the choice of just three main activities, this board design does neatly buffer each activity with a sub-column titled ‘Ready’, and is a common layout that you should be aware of as a variation.
In conclusion, we have drawn attention to important ways that Agile Board columns can be classified into principal activity, buffer and review states. We have seen that where activities are complex and expensive, you may expect a greater benefit from going into more detail on your board by adding buffer and possibly review states. Where activities are relatively quick and straightforward, you may wish to forgo such details and see if a single column for the activity will serve your needs. As ever, it is the context that decides, and it is up to you to find what setup and tweaks work optimally for your teams.
*Note: this is idleness of work, emphatically not the quite different concept of the idleness of people. The former must always be cracked down on, but the latter is a more nuanced thing; indeed, having some slack built in to people’s normal work practices is essential to allow for responsiveness. This will, again, be a topic for a future article.











 All we have done is swapped the order of the same 16 steps, so the total time to complete all four projects is the same. Did we achieve anything by parallelising? Well yes, but nothing good – we have in fact massively delayed the delivery points to our customers of three of the four projects (yellow, red and green), while blue remains unchanged. In other words, we have made 75% of our projects take longer by over-parallelising.
All we have done is swapped the order of the same 16 steps, so the total time to complete all four projects is the same. Did we achieve anything by parallelising? Well yes, but nothing good – we have in fact massively delayed the delivery points to our customers of three of the four projects (yellow, red and green), while blue remains unchanged. In other words, we have made 75% of our projects take longer by over-parallelising.




















You must be logged in to post a comment.